
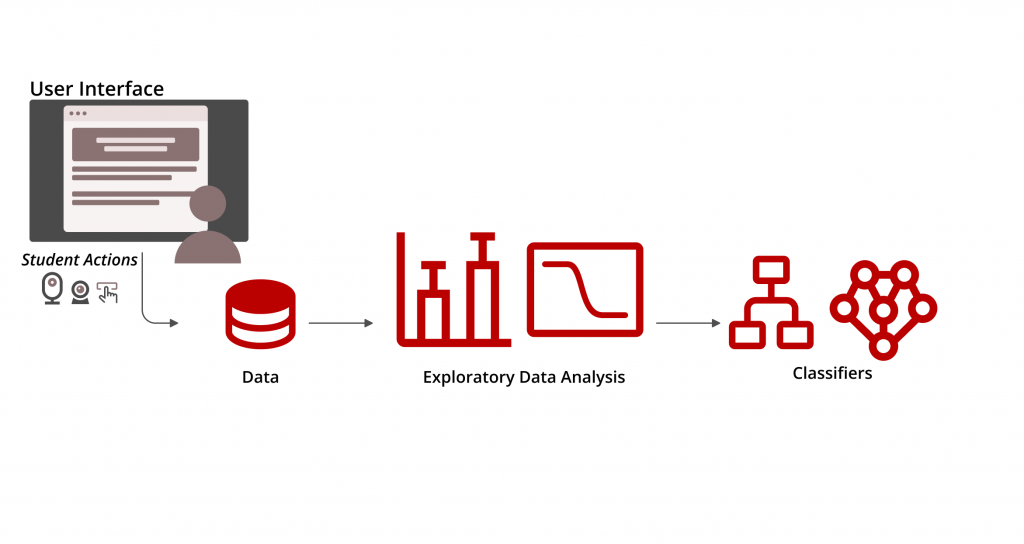

Start Any Time
Work on your pace and you will have instructors available to help you answer any questions.

Duration
Approximately 6 weeks, 3-4 hours/week
Fee
$1500 Professional Rate
$500 Full-time Student Rate


Work on your pace and you will have instructors available to help you answer any questions.
Approximately 6 weeks, 3-4 hours/week
$1500 Professional Rate
$500 Full-time Student Rate