Beginner level
No prior experience required
No prior experience required
3 weeks, 6 to 8 hours per week
Get guidance on your work
Share on LinkedIn
*Proof of full-time student enrollment required. Acceptable forms of ID include a letter from your university’s registrar office or an unofficial transcript. Email your documents to learnlab-help@lists.andrew.cmu.edu.
Educational data can reveal which learners are struggling, which patterns matter, and where instructional improvements are most needed. For many teams, the challenge is not access to data but knowing how to explore it, model it, and turn it into decisions that improve learning.
In this course, you will build a practical foundation in learning analytics by exploring educational datasets, applying regression and classification methods, and interpreting model results in context. The course is designed to help you move from descriptive reporting to evidence-based prediction that can inform interventions, product decisions, and course improvement.
At the end of the course, you'll have an opportunity to do a little project where you will analyze a dataset for predicting student success. That will provide you with a nice experience to apply the fundamentals you will learn in the modules to a larger, more authentic, context. It will be self-graded and you will receive a sample solution.
Alternatively, you may take a final exam with 20 randomized questions. The exam can be taken multiple times, and your highest score will count.
You are also free to do both the course project and the final exam, we will consider the one in which you score more for counting towards the certificate.


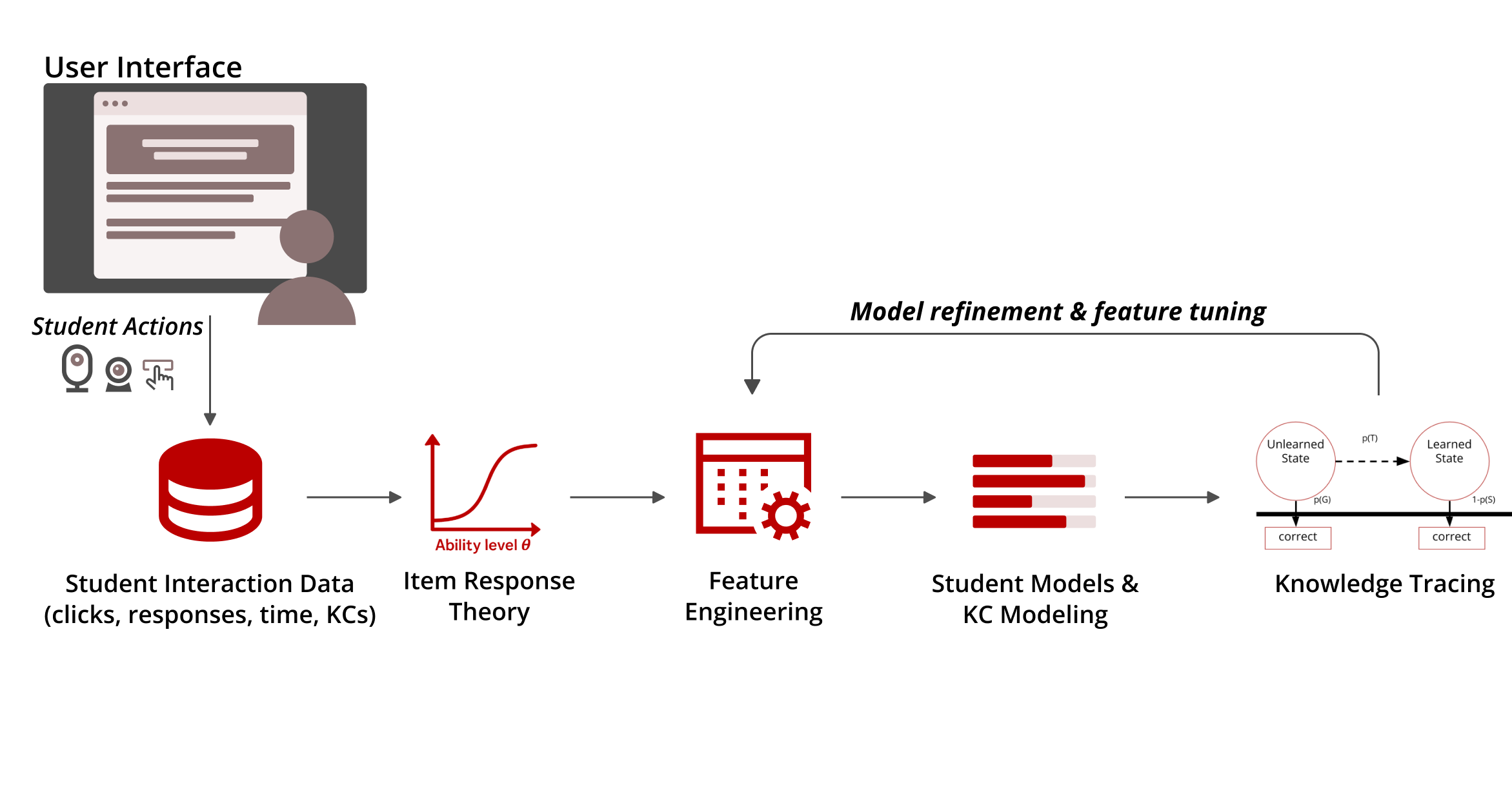
Build predictive models and use knowledge tracing to model learner progress and support adaptive learning systems.
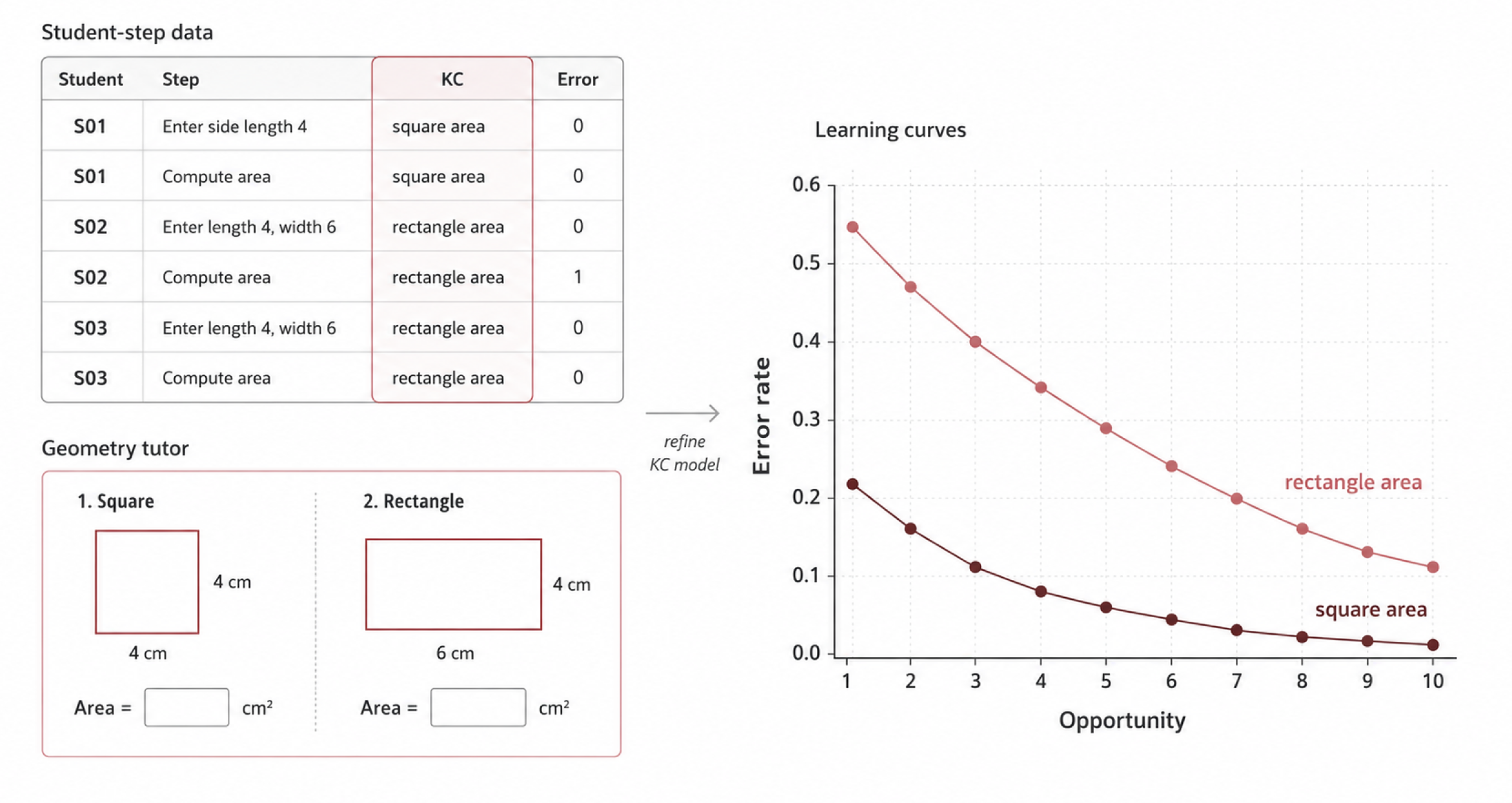
Use learning curves and educational data mining to identify learning patterns and improve course design.
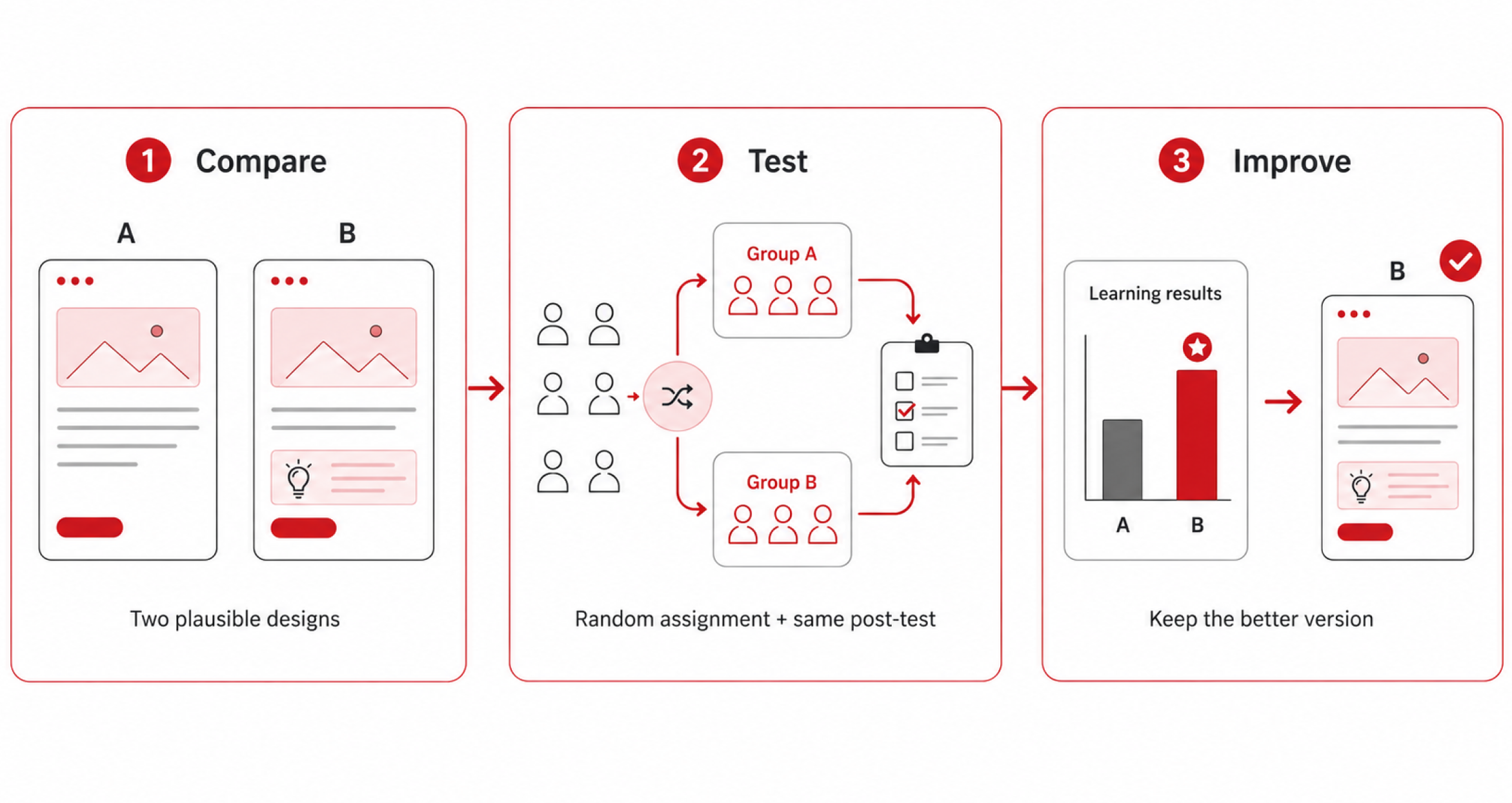
Run A/B tests to compare learning design alternatives and make evidence-based decisions about what works best.